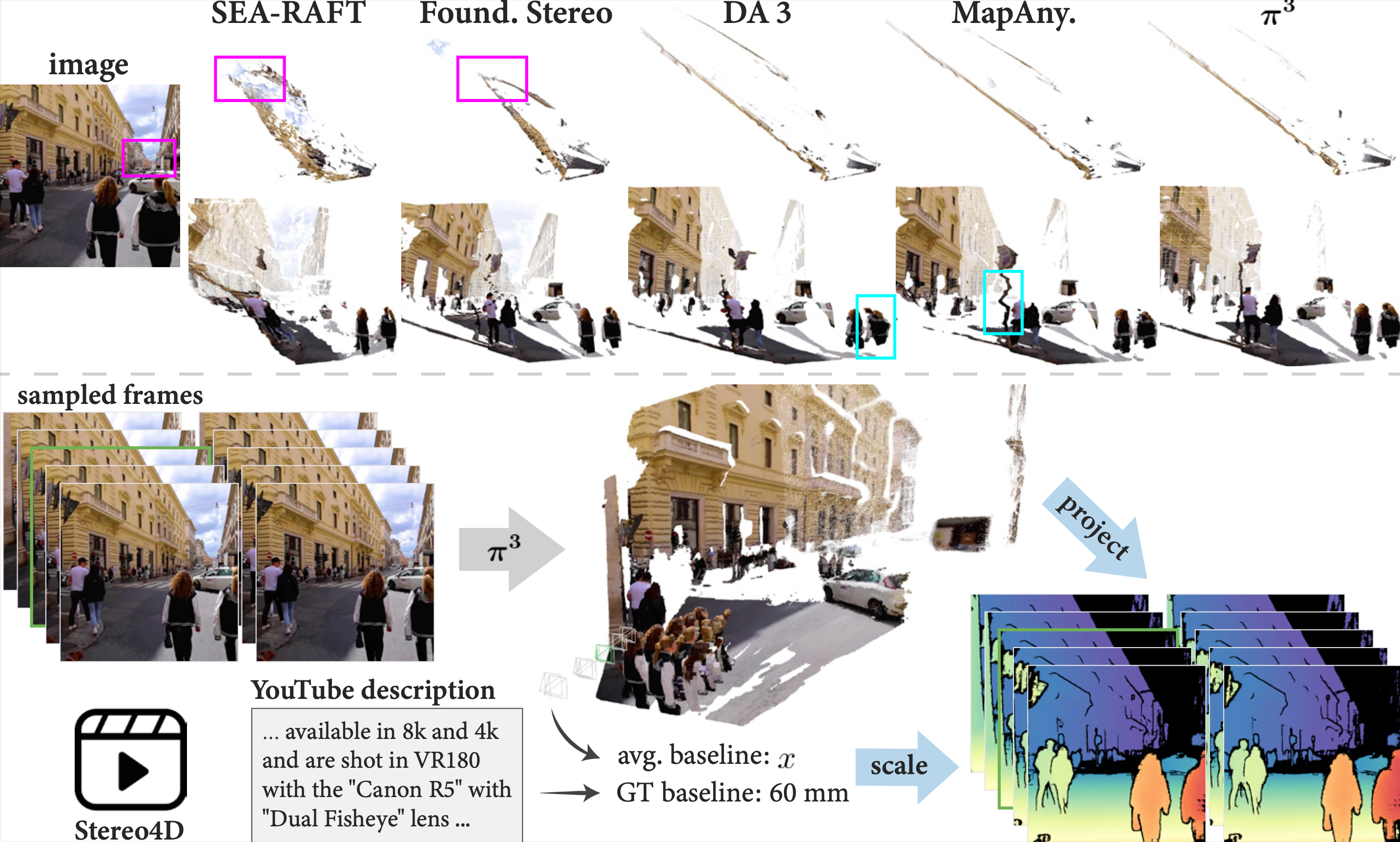
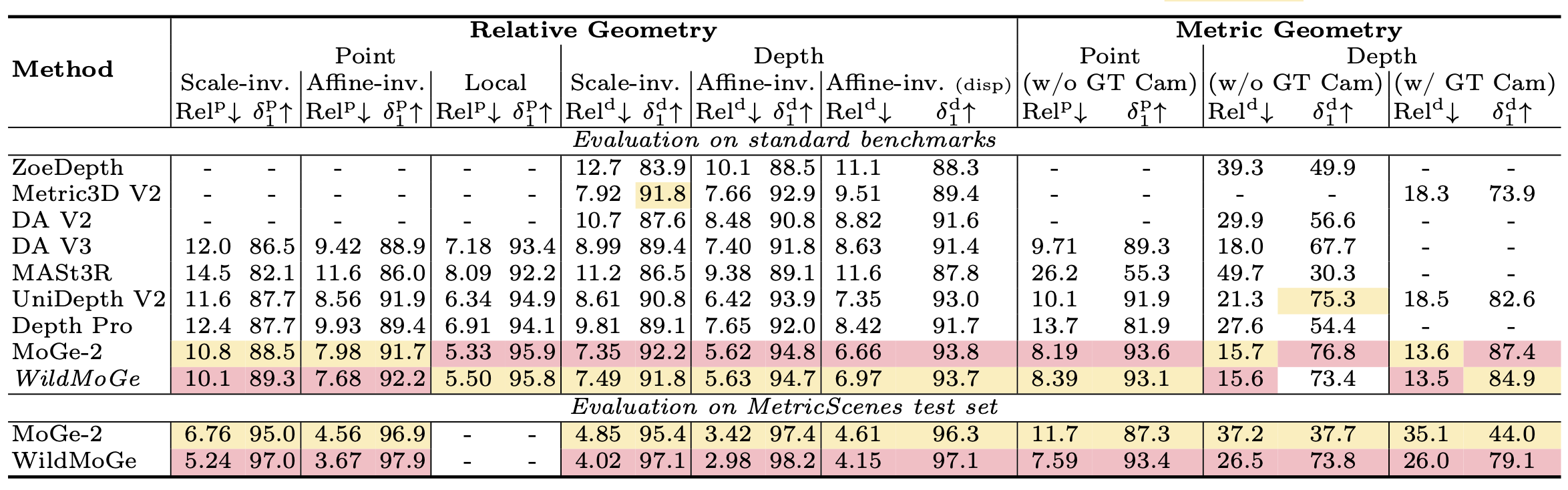
The MetricScenes Dataset
To fill critical gaps and add diversity missing in existing real-world metric datasets, we leverage widely available visual sources, including Internet photo collections and stereo imagery. These sources provide the environmental and semantic variety missing from existing hardware-constrained datasets. We reconstruct camera viewpoints and initial depth maps via off-the-shelf methods, then recover absolute physical scale by leveraging geolocated landmark metadata and stereo camera baselines. Specifically, we aggregate data from MegaScenes, AerialMegaDepth, and Stereo4D, and develop pipelines to extract metric-scale depth maps in each case.